Resumo
Neste paper realizou-se uma classificação de três classes de dispositivos médicos fabricados pela Stening®. A classificação foi realizada utilizando três algoritmos de machine learning orientados à classificação. Os algoritmos foram Support Vector Machines, Logistic Regression e Decision Tree. Com este estudo, a Stening® pretende dar a conhecer melhor seus produtos e proporcionar uma visão mais técnica deles.
Introdução
Os objetivos principais do estudo são os seguintes:
- dar a conhecer os produtos que a Stening® fabrica
- oferecer uma visão mais técnica sobre eles utilizando tecnologia inovadora
Neste escrito realizou-se uma classificação de três classes de dispositivos médicos fabricados pela Stening®. Para isso utilizaram-se três técnicas diferentes de classificação de machine learning. Trata-se de três algoritmos que fazem o mesmo, mas cujo funcionamento interno é totalmente diferente. Estes foram: Support Vector Machine (SVM), Logistic Regression (LG) e Decision Tree (DT). O funcionamento interno será explicado no fundamento teórico.
- ST (Stent Traqueal)
- TM (Tubo em T)
- SY (Stent em "Y")
Geraram-se três datasets de 900, 1200 e 1500 linhas para realizar o treinamento. Para a classificação baseamo-nos em 5 atributos diferentes, mas comuns, dos dispositivos: comprimento, diâmetro, ancoragens, número de ramos e espessura da parede. Estes 5 atributos são os que diferenciam, dentro do dataset, as três classes de dispositivo médico. A criação do dataset será explicada na seção de resultados.
Analisaremos os resultados de cada algoritmo aplicado sobre cada um dos datasets. Por último, serão dadas as conclusões e as perspectivas futuras deste estudo.
Tipo de estudo
Trata-se de um estudo computacional orientado ao setor da inteligência artificial.
Fundamento teórico
Nesta seção introduziremos os algoritmos utilizados para a classificação dos dispositivos médicos.
SVM
Nesta seção será introduzido o algoritmo Support Vector Machines [1]. Trata-se de um algoritmo de classificação pertencente ao ramo de aprendizado supervisionado. A classificação é realizada encontrando o melhor hiperplano1 em um espaço N-dimensional (N é o número de parâmetros) que separa os dados.
Para separar duas classes de dados há muitos hiperplanos possíveis. O objetivo do algoritmo é encontrar aquele que esteja à maior distância entre os dados de ambas as classes (ver figura 1).
Os hiperplanos marcam a zona onde começa uma classe e termina outra. Ou seja, se no futuro recebermos um parâmetro na zona baixa do hiperplano será da classe vermelha; se estiver na outra zona será azul. Os hiperplanos podem ser de diferentes dimensões, dependendo dos dados que tivermos. Se tivermos um conjunto de dados {x1, x2}, como na figura 1, nosso hiperplano será uma reta; se os dados dependerem de três atributos diferentes {x1, x2, x3} o hiperplano será de dimensão dois. Em outras palavras, sempre terá uma dimensão a menos que nosso conjunto de dados.
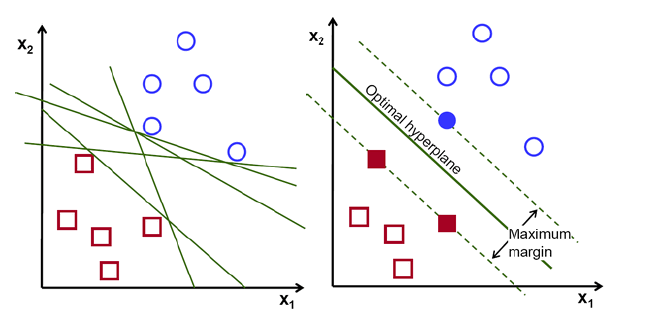
Figura 1: hiperplano para 2D [2].
Os vetores de apoio, ou support vectors, são dados próximos ao hiperplano que influenciam sua orientação e posicionamento. No SVM buscamos maximizar a margem entre os pontos e o hiperplano.
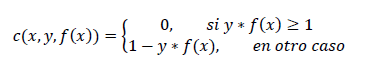
A função que nos ajudará a maximizar a margem é a seguinte:
(1)
A expressão (1) recebe o nome de função de perda (loss function). Nesta expressão, x são os dados, y é o resultado conhecido e f(x) é a predição que fazemos. Se estas duas últimas forem do mesmo sinal, a função de perda vale zero.
Este algoritmo é utilizado para realizar problemas de classificação e para fazer predições. Por exemplo, distinguir entre três tipos de flores a partir de três dados diferentes: x = {cor, largura das pétalas, altura}. Depois, a partir de aprender com os dados, o modelo deve ser capaz de predizer a que classe de flor (y) pertence uma flor com dados que não tenha visto.
Logistic Regression
A regressão logística é um método estatístico para realizar classificações [3]. É um tipo especial de regressão linear onde as classes a predizer são categóricas. Isto pode ser entendido com um exemplo: predizer se tenho uma doença ou não, as respostas seriam Sim ou Não.
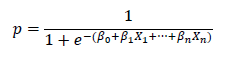
Como se disse, é um tipo especial de regressão linear. A fórmula de uma regressão linear é a seguinte:
(2)
Na expressão (2), y é o resultado da predição e X1, X2, ... são as variáveis com as quais o modelo treina. A regressão logística obtemos introduzindo (2) na seguinte expressão:
(3)
A expressão (3) recebe o nome de função Sigmoide (figura 2). Então, a regressão logística consiste em aplicar a função sigmoide a uma regressão linear.
Temos três tipos de regressões logísticas:
- Regressão logística binária: duas categorias para predizer
- Regressão logística multinomial: três ou mais categorias para predizer
- Regressão logística ordinal: três ou mais categorias para predizer, mas ordinais, ou seja, com certa ordem
Neste escrito utilizaremos a regressão logística multinomial, já que temos três classes de dispositivos médicos; não será ordinal porque carecem de ordem.
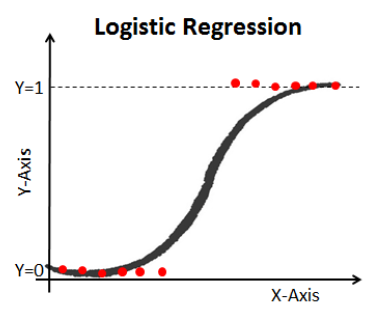
Figura 2: Representação gráfica de uma regressão logística binária [3].
Decision Tree
Uma árvore de decisão é um algoritmo amplamente utilizado, não só em Machine Learning, mas em outras áreas da computação [4]. Sua lógica resulta mais simples que a dos outros dois algoritmos, já que é mais intuitiva. Esta lógica explicaremos a seguir.
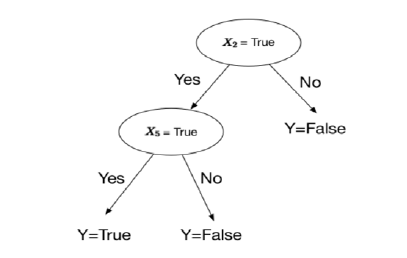
A árvore de decisão tem três componentes principais: nós, folhas e ramos. Um nó representa um atributo, um ramo representa uma decisão e uma folha (leaf) representa uma saída. O objetivo principal é gerar uma árvore de decisão que tenha tantas folhas quantas categorias você queira classificar, no nosso caso três, já que temos três tipos diferentes de dispositivo médico. A estrutura seria como a da figura 3.
Resultados
Nesta seção vamos explicar como realizamos o dataset e os resultados obtidos.
Dataset
O dataset realizamos a partir das medidas dos dispositivos originais da Stening®. Realizaram-se três datasets diferentes de 900, 1200 e 1500 linhas cada um.
Como se disse, a partir das dimensões dos dispositivos fabricados pela Stening®, fomos gerando os datasets aleatoriamente. Isso nos deu uma liberdade de treinamento para ter uma maior variedade. Isto é assim porque algumas dimensões que se incluem em seu site não são as mais vendidas e, portanto, as menos fabricadas, de modo que, se nos baseássemos nisso para gerar o dataset, por mais que estivesse mais próximo da realidade estaria enviesando o modelo e o treinamento. É por isso que, como primeira aproximação, decidimos gerar o dataset desta forma. Não obstante, como se disse, sempre dentro das dimensões reais dos dispositivos.
Na imagem a seguir podemos ver uma série de linhas do dataset de 1200:
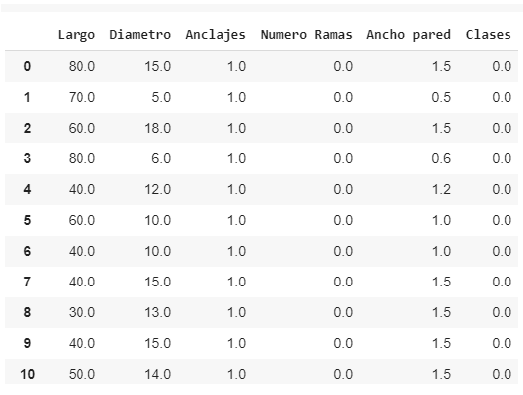
Figura 4: Primeiras 11 linhas do dataset de 1200 linhas.
Por serem 3 classes diferentes de dispositivo, atribuiu-se um número a cada uma para poder treinar os modelos. Desta forma: '0' representa um ST, '1' um TM e '2' um SY. Por sua vez, para os parâmetros binários (Sim/Não) como a coluna ("Ancoragens"), atribuiu-se um '1' se a resposta fosse 'Sim' e um '0' se a resposta fosse 'Não'.
Para a realização do dataset utilizou-se um programa escrito em Python 3.5.
Programas e resultados
Realizaram-se três programas, um para cada modelo a aplicar. A estes três programas introduziu-se cada um dos três datasets, obtendo assim três resultados por algoritmo. Estes três programas foram escritos, como o que gera o dataset, em Python 3.5. Para realizá-los utilizou-se a biblioteca de machine learning Sklearn.
Quanto aos resultados obtidos, obteve-se eficácia absoluta nos três modelos. Cada um deles foi capaz de obter uma eficácia de 100% na predição de amostras que não havia visto antes. Nas imagens seguintes podemos ver os resultados obtidos:
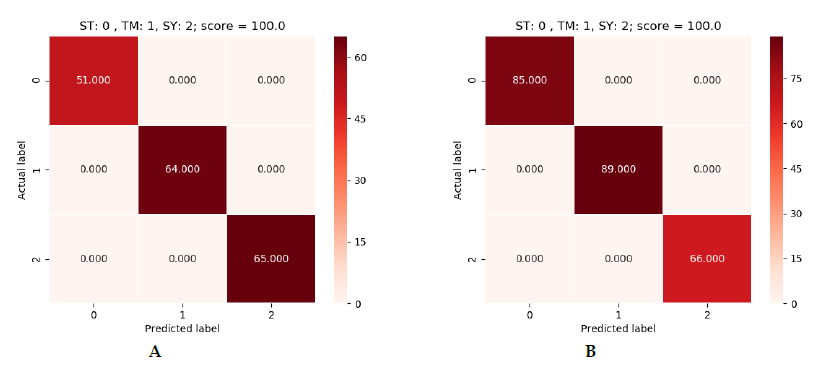
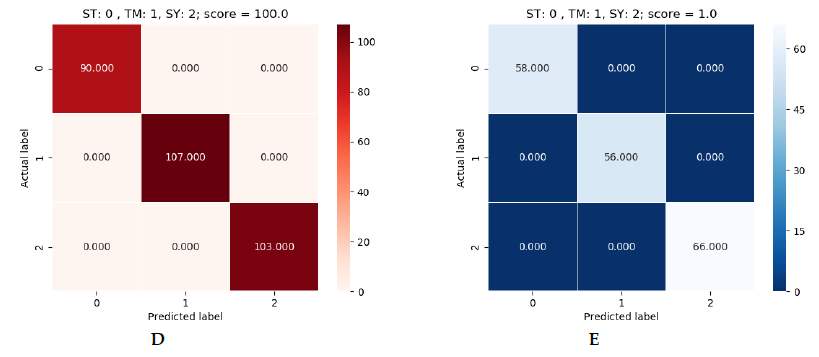
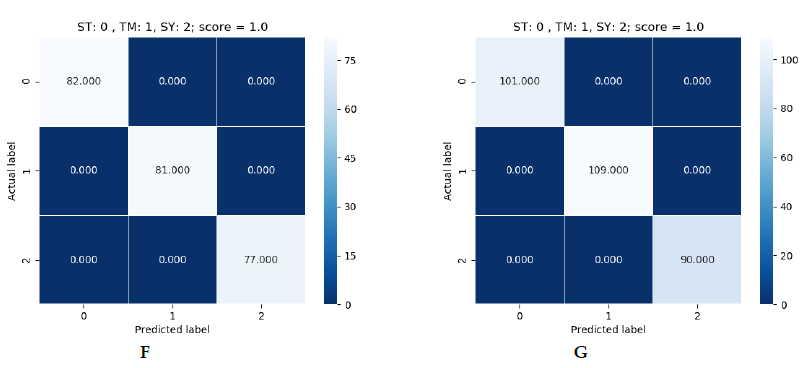
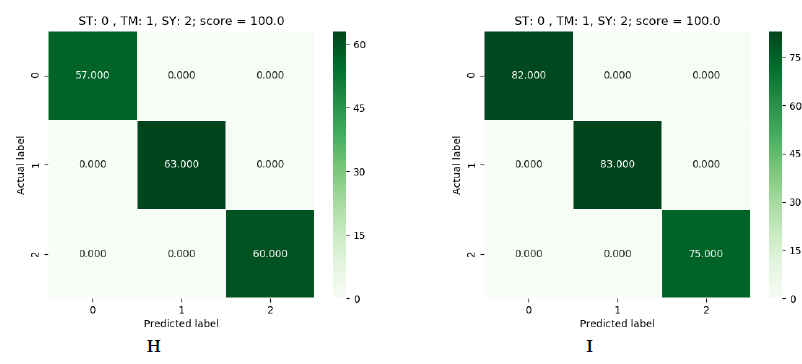
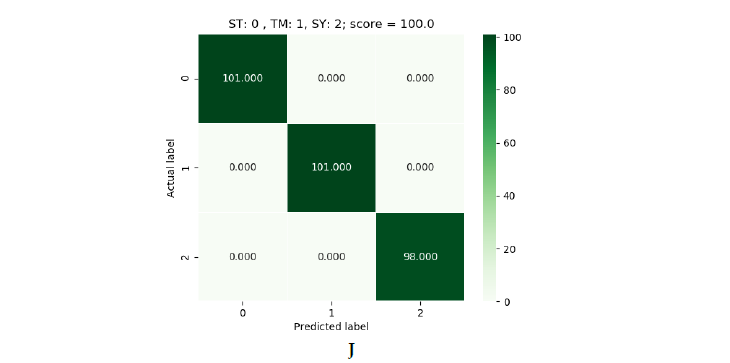
Figura 5: verde (SVM), azul (Logistic Regression) e vermelho (Decision Tree).
Na figura 5 podemos ver os resultados obtidos para cada dataset. Como se disse, há três quadros de resultados por algoritmo. Estão em ordem, sendo o primeiro o de 900 e o último o de 1500. Em cada quadro podemos ver uma referência às labels. No eixo vertical temos a label correta e no horizontal a label predita pelo modelo. No canto superior direito temos o resultado da predição. O número que aparece dentro do quadrado é o número de dispositivos preditos com essa label. Se somarmos todos os números veremos que não se obtém o total do dataset, já que estas são as predições sobre uma parte do dataset que o modelo não viu durante o treinamento. Isto se deve a que o dataset foi dividido em 70% para treinamento e 30% para realizar predições.
Conclusões
Para concluir, cabe mencionar que os resultados obtidos são muito satisfatórios. Isto nos motiva a continuar investigando e realizando estudos relacionados com o machine learning e a inteligência artificial.
Notas de rodapé
- Trata-se de um plano de dimensão N-1, sendo N a dimensão total do espaço em que estejamos (1D, 2D, 3D...)
Referências
- Support Vector Machine, https://towardsdatascience.com/support-vector-machine-introduction-to-machine-learning-algorithms-934a444fca47
- Support Vector Machine, https://towardsdatascience.com/support-vector-machine-introduction-to-machine-learning-algorithms-934a444fca47 Fig. 1
- Logistic Regression, https://www.datacamp.com/community/tutorials/understanding-logistic-regression-python
- Decision Tree, https://medium.com/deep-math-machine-learning-ai/chapter-4-decision-trees-algorithms-b93975f7a1f1
- Decision Tree, https://hackernoon.com/what-is-a-decision-tree-in-machine-learning-15ce51dc445d.